书接上回《CVE-2022-34918 netfilter 分析笔记》。
在上一篇文章中,我将360在blackhat asia 2022上提出的USMA利用方式实践于 CVE-2022-34918的利用过程中,取得了不错的利用效果,即绕过了内核诸多的防御措施。
但唯一的缺点是,上次的利用脚本需要攻击者预先知道内核中的目标函数偏移,而这往往是实际利用中最难获得的。这也正是DirtyCow,DirtyPipe这些逻辑类漏洞相比于内存损坏类漏洞最大的优势。
这篇文章我们再以CVE-2022-34918为模板,尝试让USMA在利用过程中不再依赖内核中的地址偏移,从而内存损坏型漏洞的exp能够和逻辑类漏洞一样具有普适性。
0x00. 简单回顾上次的手法
在上次的利用中,我们先通过漏洞本身提供的堆越界写原语去修改 struct user_key_payload 的 datalen 字段,从而使用keyctl syscall 从 data 中越界读取数据,得到了堆越界读原语。
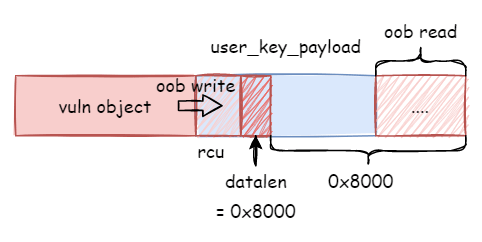
1 | struct user_key_payload { |
又由于使用 keyctl 的 KEYCTL_REVOKE 将 key 注销时,一个函数指针会被写到 struct user_key_payload 的 rcu.func 处,从而借助堆越界读原语 leak 出函数指针 user_free_payload_rcu ,再通过偏移计算出内核基地址,之后在通过偏移计算出目标函数 __sys_setresuid 的地址。
之后通过反复调用 raw packets 的 set ring 逻辑,让其不断分配 pg_vec(Line 4287),从而堆喷 pg_vec。其中 alloc_one_pg_vec_page (Line 4292)的返回值为虚拟地址页,因此 pg_vec 其实就是一个满是虚拟地址的结构体。
1 | // >>> linux-5.13/net/packet/af_packet.c:3695 |
接着我们使用漏洞本身提供的堆越界写原语去修改 pg_vec 中的页到目标函数 __sys_setresuid 所在的页,再透过 packet_mmap 将这个页映射到用户态供用户读写,从而可以直接修改内核代码。
其中注意到在mmap时存在校验,即检查page是否为匿名页,是否为Slab子系统分配的页,以及page是否含有type。因此此处我们可以选择内核代码段作为目标对象,因为他满足所有校验。
1 | // >>> mm/memory.c:1752 |
之后我们patch掉 __sys_setresuid 中的某些校验,从而让任意用户都可以透过 setresuid syscall 来提升权限到root。
1 | // >>> kernel/sys.c:652 |
阅读过360 USMA原文的朋友应该已经发现了,后面使用USMA的方法和原文相比不能说是比较类似,只能说是完全一致(笑
这一方案(指patch setresuid)的优点是省劲(指leak出指针后通过偏移直接计算出目标地址),但缺点也同样明显,即通过偏移计算地址这种方式在实际利用中可遇不可求。
有无可能让USMA做到逻辑洞那样的普适性,在不需要知道内核的任何偏移的情况下完成利用呢?
下文便是我的思考的过程。
0x01. 新朋友 fs_context
在写出上一篇文章的exploit前, 通过rcu.func来泄露内核地址并不是我第一个想到的利用对象。
CVE-2022-34918 在触发越界写时,其分配的堆块其实可以落在三种不同大小的slab中,即kmalloc-64,kmalloc-128和kmalloc-192中。当时为了找内核中有哪些会落在这三种slab中、且分配flags为 GFP_KERNEL 且比较容易分配能够堆喷的结构体时,我写了如下的CodeQL脚本用来初筛。其中过滤掉了arch和drivers目录是因为我觉得这两个目录下的结构体一般不太通用。
1 | /** |
我挨个查看得到的结果,查看是否可能包含有内核代码段地址的成员,以及是否方便堆喷。最后目光锁定到了 fs_context 这个结构体上。
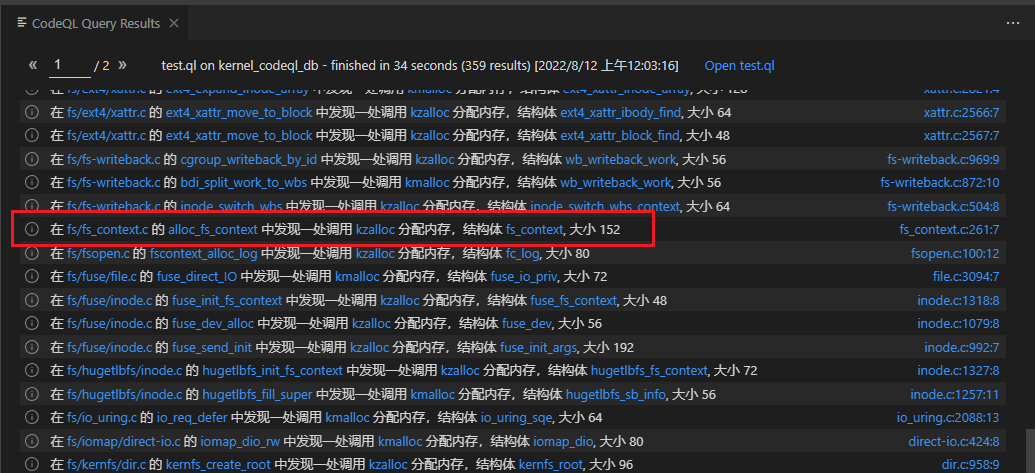
先来看一眼 fs_context 中有哪些有趣的成员吧。ops 不用多说,可以用来泄露内核基地址,也可以用来劫持控制流。等等!怎么还有cred指针? 怎么还有user_ns?没看错吧?(我当时就这表情)

1 | /* |
之后我跟了一下调用链,只需要通过简单的fsopen就能触发 fs_context 的分配:
1 | // >>> fs/fsopen.c:115 |
示例代码:
1 | // ps. should unshare user namespace first |
有一点需要额外注意!Line 257 在对 fs_context 的分配在老版本中为 GFP_KERNEL,但在新版本的内核中被改为了 GFP_KERNEL_ACCOUNT。
这是由 commit bb902cb47c 修复的(2021年9月4日),且这个commit不视为feature而是bug,因此在新的较低版本中也进行了修改。
此外,fs_context首次出现于Linux kernel 5.1中,且fsconfig syscall 首次出现与Linux kernel 5.2 中。
这里我们使用 GFP_KERNEL 的老版本。
这样我们的利用思路就发生了少许变化:先还是先通过漏洞本身提供的堆越界写原语和 struct user_key_payload 得到了堆越界读原语;之后透过 fsopen syscall 来堆喷 struct fs_context结构体,再透过之前的堆越界读原语泄露出其中的ops指针和cred指针。
一开始我想,是否能直接通过USMA去修改cred指针所在页的内容从而直接提权。但我马上否定了这个想法,因为mmap时存在校验,不能mmap slab页。
但马上我又想到了另一个思路。
前面leak出来的ops指针为内核rodata段的一个结构体,即 struct fs_context_operations。
1 | struct fs_context_operations { |
通过USMA,我们可以读取到ops地址下的这群函数指针;再次通过USMA,我们可以将这些函数所在的页mmap到用户态进行读写。
因为前面我们已经拿到了cred的地址,因此将函数的内容patch成一段修改cred结构体的shellcode;之后通过某些路径调用到这些函数就能在内核态执行我们的shellcode从而完成cred的修改。
这里我以指针 parse_param 为例,通过分析我发现可以透过 fsconfig syscall 来触发。
1 | // >>> fs/fsopen.c:314 |
示例代码:
1 | // ps. should unshare user namespace first |
下一步就是编写目标shellcode了。这里我手搓了一段shellcode来修改cred中的 uid、euid、cap_inheritable、cap_permitted、cap_effective 以及 user_ns。调用完shellcode后马上还原函数内容,防止影响到内核的正常使用。
1 | uint8_t shellcode[] = { |
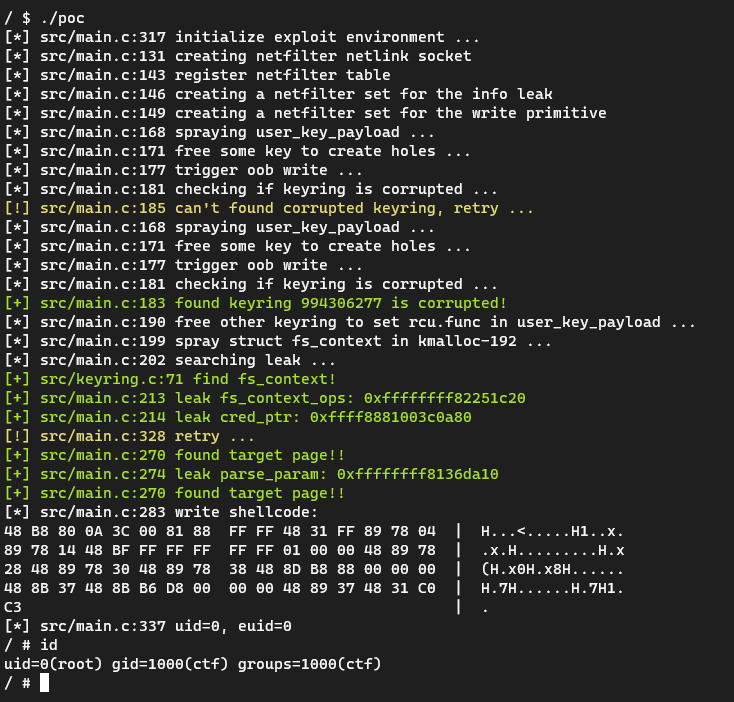
poc链接:https://github.com/veritas501/CVE-2022-34918/tree/master/poc_fs_context_cred_common
这个过程虽然使用到了内核地址,但没有使用偏移进行计算,因此只要确保内核受影响即可攻击成功,并不需要预先对内核进行分析。
可以看到 struct fs_context 确实威力不小,简简单单就leak到了进程的 cred 指针和user namespace 指针。
但正也如上面所说,struct fs_context在较新的内核中开始使用 GFP_KERNEL_ACCOUNT flags进行分配。而USMA使用的 pg_vec 使用 GFP_KERNEL 进行分配。前者会被放入 kmalloc-cg-xxx cache中,后者则放入 kmalloc-xxx cache 中。而分配这些cache时一般会一次性申请8个page(可以查看/proc/slabinfo),因此除非做好 page level 的风水,否则很难让这两个结构体在虚拟地址空间上挨在一起。
PS: struct fs_context在新版本中使用 GFP_KERNEL_ACCOUNT 分配对内核漏洞利用来说可能并不是一件坏事,因为有诸多类似 struct msg_msg的重量级选手都使用 GFP_KERNEL_ACCOUNT flags进行分配,因此leak cred可能会变得更加容易。
那如果不借助 struct fs_context 是否还能通过注入shellcode的方式进行地址无关的提权攻击呢?答案是肯定的。
0x02. ksymtab make shellcode great again
现在的问题转换成如果有了往内核注入一段任意shellcode并执行之的能力,能否完成提权并完成 namespace 逃逸?我马上想起了之前调试eBPF漏洞时的经历。
eBPF漏洞往往是绕过校验,让其能够加载任意的eBPF代码,这样就可以通过eBPF构造出内核任意地址读写的能力。借助任意地址读写,就能通过ksymtab和kstrtab两张表中的某些关系作为特征,找到init_pid_ns的地址,之后通过pid和init_pid_ns来模拟内核调用find_task_by_pid_ns函数查找task_struct的逻辑;再在task_struct中找到cred地址并修改其中的uid和euid等来进行提权。
先说说为什么能够通过ksymtab和kstrtab两张表来找到 init_pid_ns 的地址。
1 | /* |
注意到 init_pid_ns 后面跟着一行EXPORT_SYMBOL_GPL(init_pid_ns);,这表示这个符号被导出。
1 | // include/linux/export.h |
简单来说,我们以 commit_creds 为例,第一个dword表示 commit_creds 和这个dword所在地址的偏移;第一个dword表示 kstrtab中的字符串 “commit_creds” 和这个dword所在地址的偏移。
1 | __ksymtab:FFFFFFFF8271E4D4 __ksymtab_commit_creds dd 0FE9B37ACh |
因此在利用时,我们先在内核空间暴力搜索字符串”commit_creds”,commit_creds 的 strtab 地址,在通过关系 &symtab.name_offset + symtab.name_offset == &strtab 找到 commit_creds 的 symtab 地址。之后通过加减 symtab.value_offset 就能得到 commit_creds 地址。
通过阅读内核代码,我发现 prepare_kernel_cred 和 commit_creds 均为导出函数,都可以通过上面的方法定位函数地址。因此如果我们的目标只是提权,只需要通过shellcode查找并调用这两个函数即可完成通用提权。
但如果想要改变namespace就没这么容易了。先看看平时用ROP逃逸namespace时都调用了那些函数:
1 | uint64_t chain[] = { |
这下面的 switch_task_namespaces, find_task_by_vpid ,init_nsproxy 都不是导出的,都无法通过symtab找到。
不过也只是多绕几个弯的问题。
find_task_by_vpid 是通过pid找到对应的struct task_struct:
1 | struct task_struct *find_task_by_vpid(pid_t vnr) |
我们可以通过以下两个导出函数等价替换:
1 | struct pid *find_vpid(int nr) |
即:
1 | find_task_by_vpid(1) == pid_task(find_vpid(1), PIDTYPE_PID) |
switch_task_namespaces 干的事情也很单一,如果我们能够知道 nsproxy 在 task_struct 中的偏移,只要用shellcode手动替换一下也是一样的,并不需要调用函数。
1 | void switch_task_namespaces(struct task_struct *p, struct nsproxy *new) |
init_nsproxy 的寻找就比较leet了。首先注意到 init_pid_ns 是导出的,起切中包含 init_task 的地址。
1 | struct pid_namespace init_pid_ns = { |
而 init_task 中又存在 init_nsproxy 的地址
1 | struct task_struct init_task |
1 | struct nsproxy init_nsproxy = { |
因此,理论上,通过偏移我们是能够顺着 init_pid_ns 找到 init_nsproxy 的地址的。
但,这只是理论上。
从 init_pid_ns 摸到 init_task 没啥大问题,struct pid_namespace 基本不会发生代码变动,因此指针偏移可以认为不变。但从 struct task_struct 摸到 init_nsproxy 如果也直接通过偏移找就太不靠谱了,因为 struct task_struct 在不同版本间经常变动,且在同一版本中也会受不同编译参数的影响而发生变化。因此这里我依然打算通过指针间的特征来找。
首先是从init_pid_ns 寻找 init_task。所用的逻辑特征是 init_pid_ns 中存在一个指针p1,将其视为task_struct,其中包含自身地址p1。
1 |
|
从 init_task 找到 init_nsproxy的逻辑特征为 init_task 中存在一个指针p1,其不等于 init_task 自身,将其视为nsproxy,其中同时存在 init_pid_ns 和 init_uts_ns 两个指针。且通过这个特征可以得知nsproxy在task_struct中所在偏移,之后便可以通过shellcode直接对目标task struct的nsproxy进行修改。
1 |
|
但上述逻辑如果要完全手动用汇编来写shellcode未免实在太困难,因此这里我直接用C来写shellcode:
1 | typedef unsigned long size_t; |
为了得到尽可能短的shellcode,我用了clang的-Oz来编译,并再加上了不少优化来缩小shellcode体积:
1 |
|
最后得到如下的shellcode,还是有点长,一共有0x260多个字节。
1 | unsigned char shellcode[] = { |
我先是把上面这段shellcode覆盖 fs_context 的 parse_param 函数,即可不依赖cred泄露完成提权和逃逸:
poc链接:https://github.com/veritas501/CVE-2022-34918/tree/master/poc_fs_context_common
但当我将上面这段shellcode用于覆盖 user_key_payload 的 user_free_payload_rcu 函数时内核发生了崩溃。通过调试发现,是因为shellcode的宿主 user_free_payload_rcu 函数体积太小,不够存放完整的shellcode,因此shellcode覆盖到了后面的函数,而后面的函数会先于 user_free_payload_rcu 调用,因此执行到了非法指令。解决方法是在shellcode前面放入一定长度nop雪橇(nop sled),从而能够在执行到后面的函数时直接“滑”到我们的shellcode上。
poc链接:https://github.com/veritas501/CVE-2022-34918/tree/master/poc_keyring_common
PS. 其实提权的shellcode不止这一种,例如也可以通过调用导出函数call_usermodehelper来提权,由于这种方法比较简单,这里留给读者来尝试与思考。
1 | /** |
0x03. 总结
随着越来越多的软硬件缓释措施不断部署,我们可以发现传统的ROP,JOP利用技术越来越难以攻破现有系统。当几年前的我听到shadow stack,control-flow guard等防御时,我曾一度以为未来漏洞利用将变成一件几乎不可能的事情。
但恰恰相反的是,我幸运地见证了越来越多新型攻击技术的诞生。例如数年前对eBPF的攻击去构造内核任意地址读写,亦或是去年 Google 的 Jin Xingyu 学长提出的 ret2bpf技术,又如今年360在BlackHat Asia上提出的USMA技巧,由DirtyPipe启发而来的Pipe原语,美国西北大学即将公开的DirtyCred技术等等。这些新型攻击技术无不为我展示了漏洞利用无穷的可能性,也让我感觉到漏洞利用中的那种艺术的美感。
最后还是那句话,纸上得来终觉浅,绝知此事要躬行。
